Narzędzia AI do programowania zmieniają tempo pracy zespołów developerskich. Jeszcze niedawno największym ograniczeniem było samo tworzenie kodu: analiza zadania, przygotowanie implementacji, napisanie testów i poprawienie błędów. Dziś coraz częściej ten etap jest przyspieszany przez asystentów i agentów AI, które potrafią wygenerować fragment funkcji, test, migrację, refaktoryzację albo nawet cały pull request.
To dobra wiadomość dla firm, które chcą szybciej rozwijać produkty. Jest jednak druga strona tego trendu. Jeżeli organizacja zaczyna produkować więcej kodu, ale nie zmienia sposobu jego sprawdzania, wąskie gardło przesuwa się z developmentu do walidacji. Problemem przestaje być to, czy zespół potrafi napisać zmianę. Problemem staje się to, czy pipeline CI/CD potrafi szybko, tanio i wiarygodnie odpowiedzieć na pytanie: czy ta zmiana nadaje się do wdrożenia?
W praktyce wiele firm odkryje, że ich pipeline’y były projektowane dla wcześniejszej skali pracy. Działały poprawnie, gdy zespół tworzył kilka lub kilkanaście pull requestów dziennie. Zaczynają jednak tracić wydolność, gdy AI zwiększa liczbę zmian, eksperymentów, branchy, buildów i testów. Wtedy pojawiają się kolejki, rosną koszty runnerów, buildy trwają coraz dłużej, testy przestają być wiarygodne, a developerzy zaczynają traktować CI/CD jako przeszkodę zamiast wsparcia.

AI nie usuwa potrzeby walidacji. Ono ją zwiększa
Wdrożenie AI do programowania bywa przedstawiane jako sposób na zwiększenie produktywności developerów. To prawda, ale tylko częściowo. AI przyspiesza generowanie kodu, natomiast nie zwalnia organizacji z odpowiedzialności za jakość, bezpieczeństwo, zgodność architektoniczną i stabilność produktu.
Kod wygenerowany przez AI może wyglądać poprawnie. Może przechodzić podstawową kompilację. Może nawet zawierać testy. Nie oznacza to jednak, że jest zgodny z logiką biznesową, architekturą systemu, wymaganiami bezpieczeństwa i standardami organizacji. W wielu przypadkach wymaga takiej samej, a czasem nawet większej kontroli niż kod napisany ręcznie.
Dlatego firmy, które realnie chcą korzystać z AI w software delivery, powinny przestać zadawać pytanie wyłącznie o to, jak szybciej pisać kod. Ważniejsze pytanie brzmi: jak szybciej i pewniej sprawdzać większą liczbę zmian?
To właśnie pipeline CI/CD staje się jednym z najważniejszych elementów całego procesu. Jeżeli jest dobrze zaprojektowany, AI może przyspieszyć development bez utraty kontroli. Jeżeli jest przestarzały, AI tylko zwiększy chaos: więcej pull requestów, więcej nieprzewidzianych interakcji, więcej fałszywych alarmów i więcej czasu spędzonego na wyjaśnianiu, dlaczego coś nie przeszło walidacji.
Typowe objawy przeciążonego pipeline’u
Pierwszym objawem jest wydłużający się czas oczekiwania na wynik. Developer tworzy zmianę w kilka minut, ale pipeline potrzebuje kilkudziesięciu minut, żeby dać informację zwrotną. W świecie AI to szczególnie problematyczne, bo tempo iteracji jest większe. Jeżeli feedback przychodzi zbyt późno, kolejne zmiany mogą powstawać na błędnych założeniach.
Drugim objawem są kolejki buildów. Gdy liczba uruchomień rośnie, a infrastruktura CI/CD nie skaluje się dynamicznie, zespoły zaczynają czekać nie na wynik testów, ale na samo rozpoczęcie pipeline’u. To marnuje czas i obniża zaufanie do automatyzacji.
Trzecim objawem są rosnące koszty. Więcej zmian oznacza więcej buildów, więcej pobieranych zależności, więcej obrazów kontenerowych, więcej środowisk testowych i więcej minut pracy runnerów. Bez optymalizacji cache, selektywnego testowania i autoskalowania koszt CI/CD może rosnąć szybciej niż realna wartość dostarczana przez AI.
Czwartym objawem są flaky tests, czyli testy, które raz przechodzą, a raz nie, bez jednoznacznej przyczyny w kodzie. Przy większej liczbie zmian ich wpływ staje się znacznie bardziej dotkliwy. Jeżeli pipeline nie jest wiarygodny, developerzy zaczynają go ignorować, ponawiać losowo albo obchodzić.
Piątym objawem jest presja na pomijanie etapów kontroli jakości. Gdy pipeline jest zbyt wolny, zespoły zaczynają szukać skrótów: wyłączają testy, zmniejszają zakres skanów, łączą zmiany ręcznie albo przenoszą walidację na późniejszy etap. To krótkoterminowo poprawia tempo, ale długoterminowo zwiększa ryzyko awarii, regresji i problemów bezpieczeństwa.
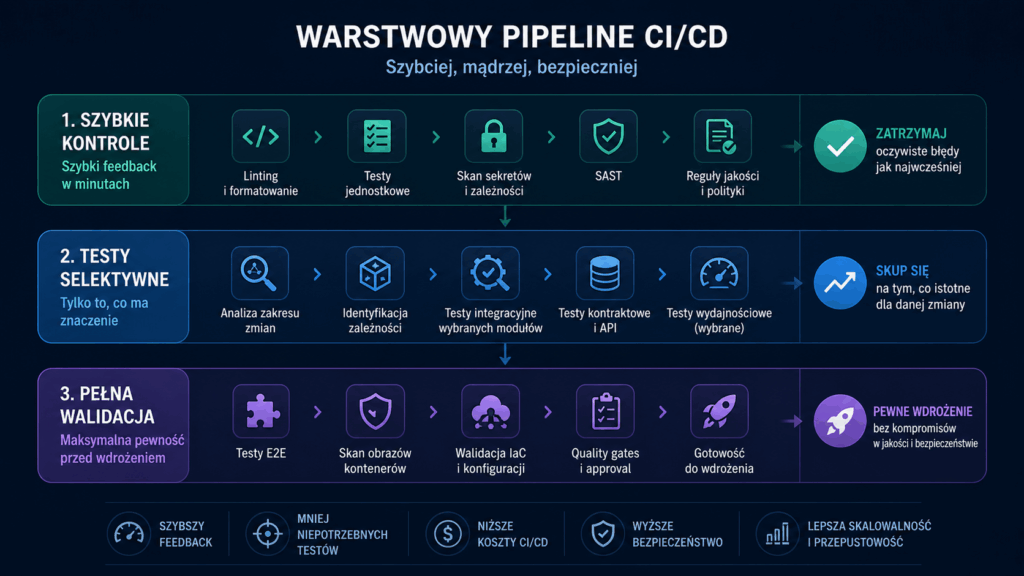
Pipeline powinien być warstwowy
Najważniejsza zmiana w podejściu do CI/CD polega na odejściu od jednego, ciężkiego procesu walidacji dla każdej zmiany. W świecie większej ilości kodu taki model szybko staje się nieefektywny. Zamiast tego pipeline powinien być warstwowy.
Pierwsza warstwa to szybkie kontrole wykonywane jak najwcześniej. Powinny obejmować linting, formatowanie, podstawowe testy jednostkowe, wykrywanie sekretów, podstawowe skany bezpieczeństwa, walidację konfiguracji i sprawdzenie prostych reguł jakościowych. Ich zadaniem jest szybkie zatrzymanie oczywistych błędów.
Druga warstwa to testy zależne od zakresu zmiany. Jeżeli pull request dotyczy tylko jednego modułu, nie zawsze trzeba uruchamiać cały zestaw testów dla całego systemu. Warto wdrożyć mechanizmy rozpoznające, które komponenty zostały zmienione, jakie zależności są dotknięte i które testy rzeczywiście mają sens. To szczególnie ważne w monorepo i większych systemach mikroserwisowych.
Trzecia warstwa to pełna walidacja przed scaleniem lub wdrożeniem. Tu powinny znaleźć się kosztowniejsze etapy: testy integracyjne, contract tests, testy end-to-end, skany obrazów kontenerowych, walidacja IaC, testy migracji, testy wydajnościowe i finalne quality gates.
Taki podział pozwala zachować równowagę. Developer szybko dostaje informację o typowych błędach, a organizacja nadal zachowuje mocną kontrolę przed merge’em lub deploymentem. To podejście lepiej pasuje do świata, w którym AI zwiększa liczbę zmian, ale firma nie chce proporcjonalnie zwiększać kosztów walidacji.
Selektywne testowanie staje się koniecznością
Jednym z najważniejszych elementów nowoczesnego pipeline’u jest selektywne uruchamianie testów. W prostych projektach można jeszcze uruchamiać wszystko za każdym razem. W większych systemach, szczególnie tam, gdzie pojawia się więcej kodu generowanego przez AI, takie podejście staje się kosztowne i wolne.
Selektywne testowanie wymaga zrozumienia struktury systemu. Pipeline powinien wiedzieć, które moduły zależą od siebie, jakie testy pokrywają konkretną część aplikacji i które zmiany mogą mieć wpływ na konkretne usługi. Dzięki temu drobna zmiana w dokumentacji lub prostym komponencie nie musi uruchamiać pełnej walidacji całej platformy.
To nie oznacza rezygnacji z jakości. Wręcz przeciwnie. Dobrze zaprojektowane selektywne testowanie zwiększa skuteczność pipeline’u, bo pozwala częściej uruchamiać właściwe testy zamiast rzadko uruchamiać wszystko. Pełna walidacja nadal powinna istnieć, ale nie musi być wykonywana przy każdym najmniejszym kroku.
Runnerzy, cache i koszty CI/CD
Większa liczba zmian oznacza większe obciążenie infrastruktury CI/CD. Dlatego firmy powinny przeanalizować, czy ich runnerzy, workery i środowiska wykonawcze są gotowe na większy ruch.
W praktyce warto zadbać o autoskalowanie runnerów, równoległe wykonywanie zadań, efektywny cache zależności, cache warstw obrazów kontenerowych, ponowne wykorzystywanie artefaktów oraz sensowne timeouty. Często duże oszczędności można uzyskać nie przez kupowanie większej infrastruktury, ale przez usunięcie niepotrzebnej pracy.
Przykładowo, jeżeli każdy pipeline pobiera od zera te same zależności, buduje od nowa te same obrazy i uruchamia te same testy niezależnie od zakresu zmiany, to AI szybko zwielokrotni ten koszt. Jeżeli natomiast pipeline korzysta z cache, potrafi pomijać niepotrzebne etapy i skaluje runnerów tylko wtedy, gdy faktycznie jest taka potrzeba, wzrost liczby zmian jest łatwiejszy do opanowania.
Merge queue i kontrola współbieżności
Przy większej liczbie pull requestów rośnie ryzyko konfliktów między zmianami. Każda zmiana może przejść testy osobno, ale po połączeniu z innymi zmianami może zepsuć główną gałąź. To klasyczny problem w środowiskach o wysokiej przepustowości.
Dlatego coraz ważniejsze stają się mechanizmy takie jak merge queue, batchowanie zmian i kontrola współbieżności. Ich zadaniem jest uporządkowanie procesu scalania kodu. Zamiast pozwalać na chaotyczne merge’owanie wielu zmian jednocześnie, system powinien sprawdzać je w kontrolowanej kolejności albo grupach, z uwzględnieniem aktualnego stanu głównej gałęzi.
To szczególnie ważne w organizacjach, które chcą korzystać z AI nie tylko jako pomocy w edytorze, ale jako elementu szerszej automatyzacji pracy developerskiej. Więcej automatycznie przygotowanych zmian wymaga bardziej zdyscyplinowanego procesu integracji.
Środowiska tymczasowe dla pull requestów
Kolejnym elementem są ephemeral environments, czyli tymczasowe środowiska tworzone automatycznie dla pull requestów lub branchy. Pozwalają one szybciej sprawdzać działanie zmian w warunkach zbliżonych do rzeczywistych, bez blokowania wspólnych środowisk developerskich.
Dla aplikacji webowych, systemów mikroserwisowych i środowisk Kubernetes może to być bardzo duża zmiana jakościowa. Reviewer, tester albo product owner może wejść na dedykowany adres i zobaczyć zmianę bez ręcznego uruchamiania środowiska. Pipeline może wykonać testy integracyjne w izolowanym kontekście. Po zakończeniu pracy środowisko jest automatycznie usuwane.
W świecie AI takie podejście pomaga utrzymać porządek. Jeżeli powstaje więcej eksperymentalnych zmian, nie powinny one wszystkie trafiać na jedno wspólne środowisko testowe. Izolacja ogranicza konflikty, poprawia powtarzalność testów i ułatwia ocenę konkretnego pull requesta.
Bez obserwowalności pipeline’u nie da się nim zarządzać
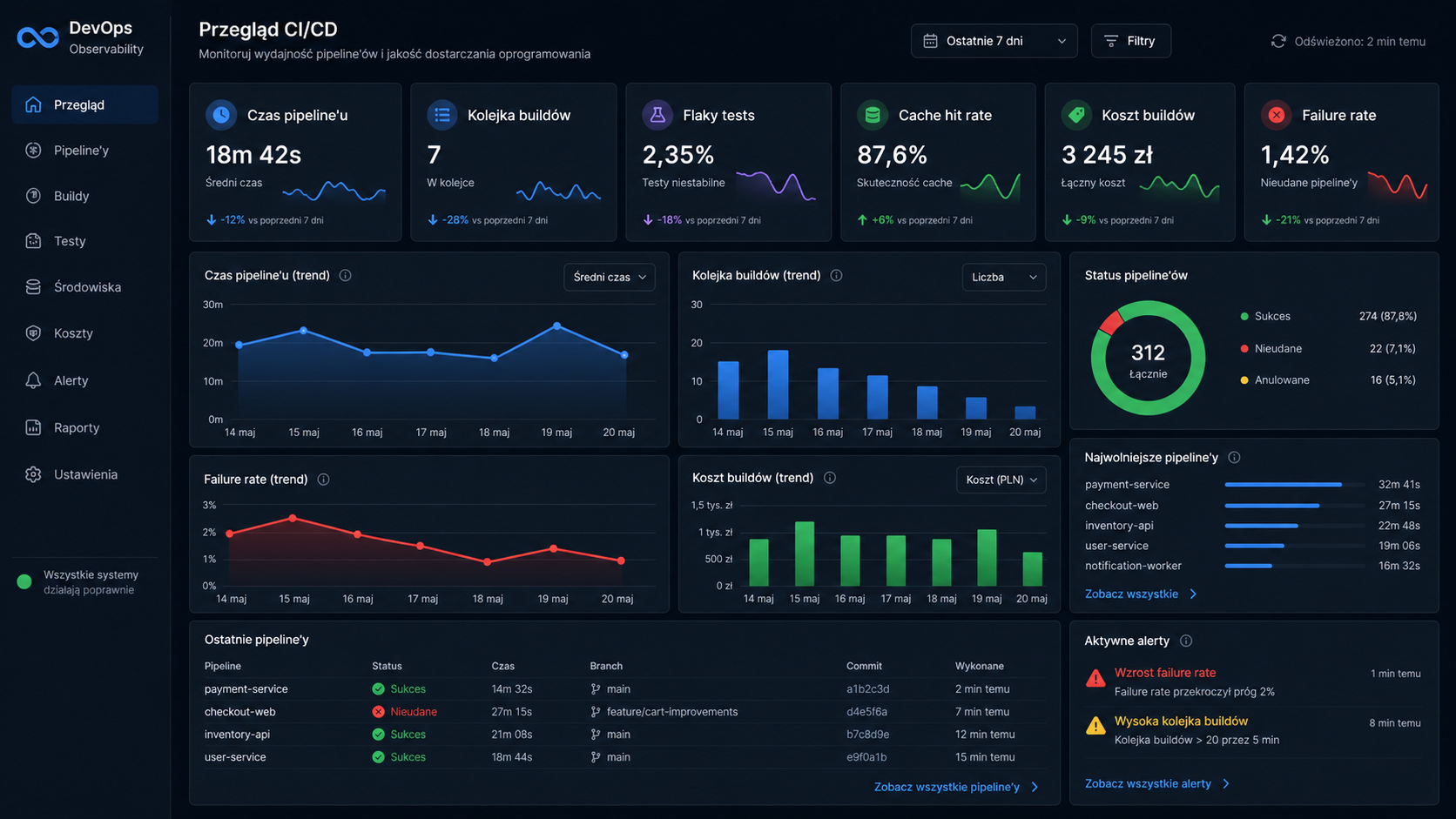
Pipeline CI/CD również wymaga monitoringu. Wiele firm mierzy dostępność aplikacji produkcyjnych, ale nie mierzy jakości własnego procesu delivery. To błąd, bo bez danych trudno wskazać, gdzie naprawdę znajduje się wąskie gardło.
Warto monitorować czas trwania pipeline’ów, czas oczekiwania w kolejce, koszt wykonania buildów, skuteczność cache, liczbę ponownych uruchomień, failure rate dla poszczególnych etapów, liczbę flaky tests, lead time od pull requesta do merge’a oraz częstotliwość wdrożeń. Takie metryki pozwalają odróżnić realny problem od intuicji.
Czasem zespołowi wydaje się, że potrzebuje większej liczby runnerów, ale prawdziwym problemem jest brak cache. Innym razem problemem nie jest długość testów, ale to, że uruchamiają się zbyt często i w zbyt szerokim zakresie. Zdarza się też, że najważniejszym ograniczeniem są testy niestabilne, przez które wynik pipeline’u nie jest traktowany jako wiarygodny.
Dopiero obserwowalność pozwala zarządzać CI/CD tak, jak zarządza się inną krytyczną infrastrukturą IT.
AI wymaga mocniejszych standardów engineeringowych
Im więcej kodu generuje AI, tym ważniejsze stają się standardy. To może wydawać się paradoksalne, ale automatyzacja nie zastępuje zasad. Ona sprawia, że brak zasad szybciej prowadzi do problemów.
Organizacja powinna mieć jasne template’y pipeline’ów, wspólne reusable workflows, standardy nazewnictwa, zasady wersjonowania artefaktów, reguły branchowania, polityki bezpieczeństwa, konwencje testowania i mechanizmy policy as code. Dzięki temu AI działa w środowisku, które ma czytelne granice.
Jeżeli każdy zespół buduje pipeline inaczej, każdy projekt ma inne quality gates, a reguły bezpieczeństwa są rozproszone po skryptach, wzrost liczby zmian tylko pogłębi chaos. Jeżeli natomiast pipeline’y są ustandaryzowane, łatwiej je optymalizować, monitorować i rozwijać.
Co to oznacza dla firm
Z biznesowego punktu widzenia temat nie dotyczy wyłącznie developer experience. Chodzi o zdolność firmy do bezpiecznego zwiększania tempa dostarczania oprogramowania.
AI może przyspieszyć tworzenie kodu, ale przewagę konkurencyjną uzyskają te organizacje, które potrafią zwiększyć cały przepływ od pomysłu do produkcji. Jeżeli pipeline nie nadąża, większa ilość kodu nie oznacza większej liczby wdrożonych funkcji. Może oznaczać większą kolejkę rzeczy do sprawdzenia.
Dlatego przystosowanie CI/CD do rosnącej ilości kodu generowanego przez AI powinno być traktowane jako inwestycja w skalowalność procesu wytwarzania oprogramowania. To nie jest wyłącznie zadanie dla administratora systemu CI. To temat dla CTO, dyrektorów IT, liderów engineeringu i osób odpowiedzialnych za efektywność delivery.
Podsumowanie
Rosnąca ilość kodu generowanego przez AI nie jest problemem sama w sobie. Problem pojawia się wtedy, gdy organizacja zwiększa tempo tworzenia zmian, ale nie zwiększa dojrzałości procesu ich walidacji.
Pipeline CI/CD staje się dziś jednym z najważniejszych elementów infrastruktury developerskiej. Musi być szybki, warstwowy, skalowalny, obserwowalny i dopasowany do ryzyka konkretnej zmiany. Musi umieć odróżniać proste poprawki od zmian krytycznych. Musi dawać szybki feedback, ale jednocześnie chronić jakość, bezpieczeństwo i stabilność produktu.
Firmy, które przygotują CI/CD na większą skalę pracy, będą mogły wykorzystać AI jako realny akcelerator software delivery. Firmy, które tego nie zrobią, mogą odkryć, że AI przyspieszyło tylko jeden etap procesu, a cała reszta zaczęła działać wolniej.
W świecie AI nie wygrają organizacje, które generują najwięcej kodu. Wygrają te, które potrafią ten kod szybko, bezpiecznie i powtarzalnie dostarczać na produkcję.